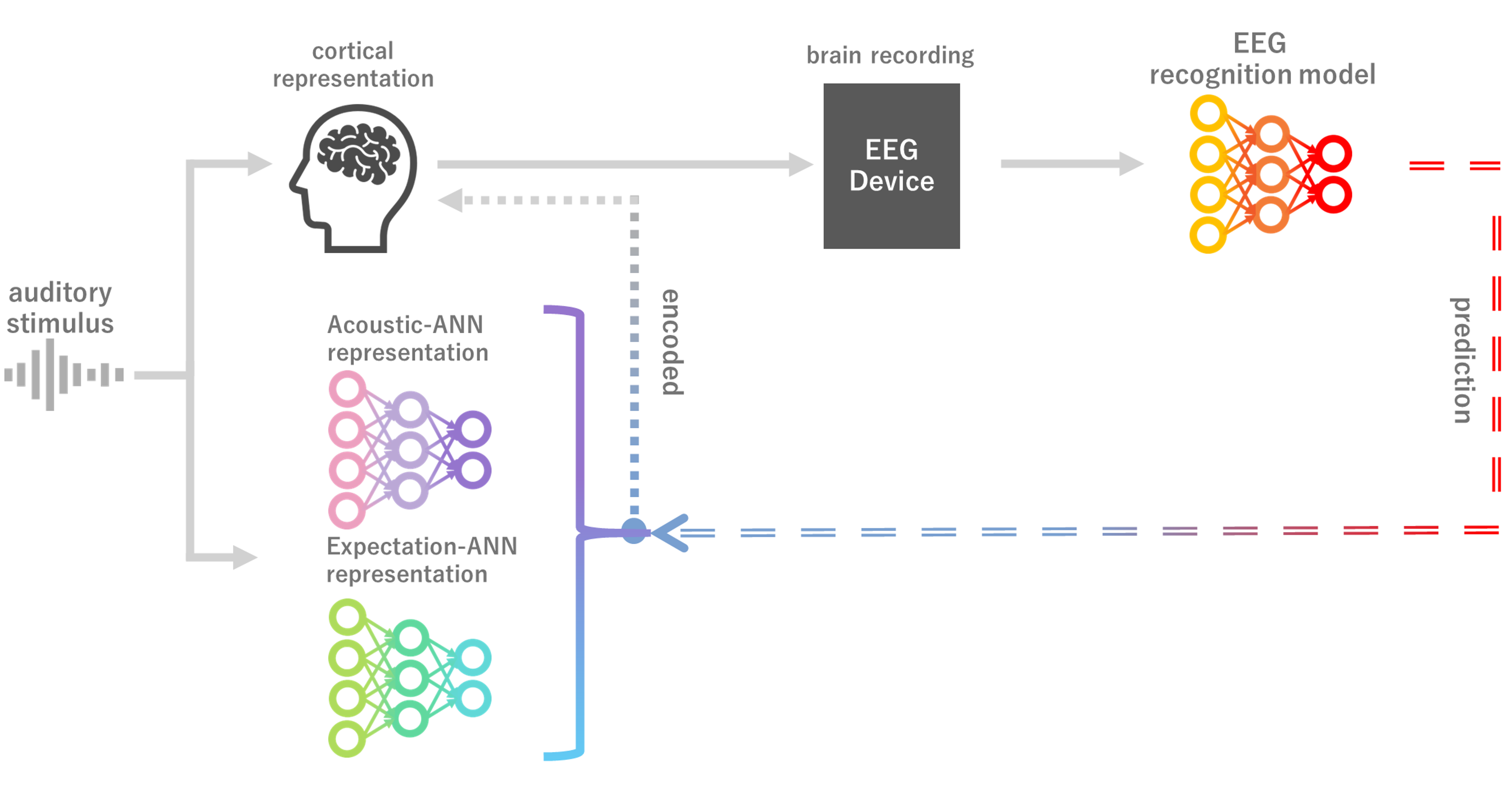
Concept.
PredANN++ aligns EEG with acoustic and expectation-related teacher signals, then combines the resulting models for complementary gains.
Neural encoding can guide EEG representation learning.
During music listening, cortical activity encodes both acoustic and expectation-related information. Prior work has shown that ANN representations resemble cortical representations and can serve as supervisory signals for EEG recognition. Here we show that distinguishing acoustic and expectation-related ANN representations as teacher targets improves EEG-based music identification. Models pretrained to predict either representation outperform non-pretrained baselines, and combining them yields complementary gains that exceed strong seed ensembles formed by varying random initializations. These findings show that teacher representation type shapes downstream performance and that representation learning can be guided by neural encoding. This work points toward advances in predictive music cognition and neural decoding. Our expectation representation, computed directly from raw signals without manual labels, reflects predictive structure beyond onset or pitch, enabling investigation of multilayer predictive encoding across diverse stimuli. Its scalability to large, diverse datasets further suggests potential for developing general-purpose EEG models grounded in cortical encoding principles.
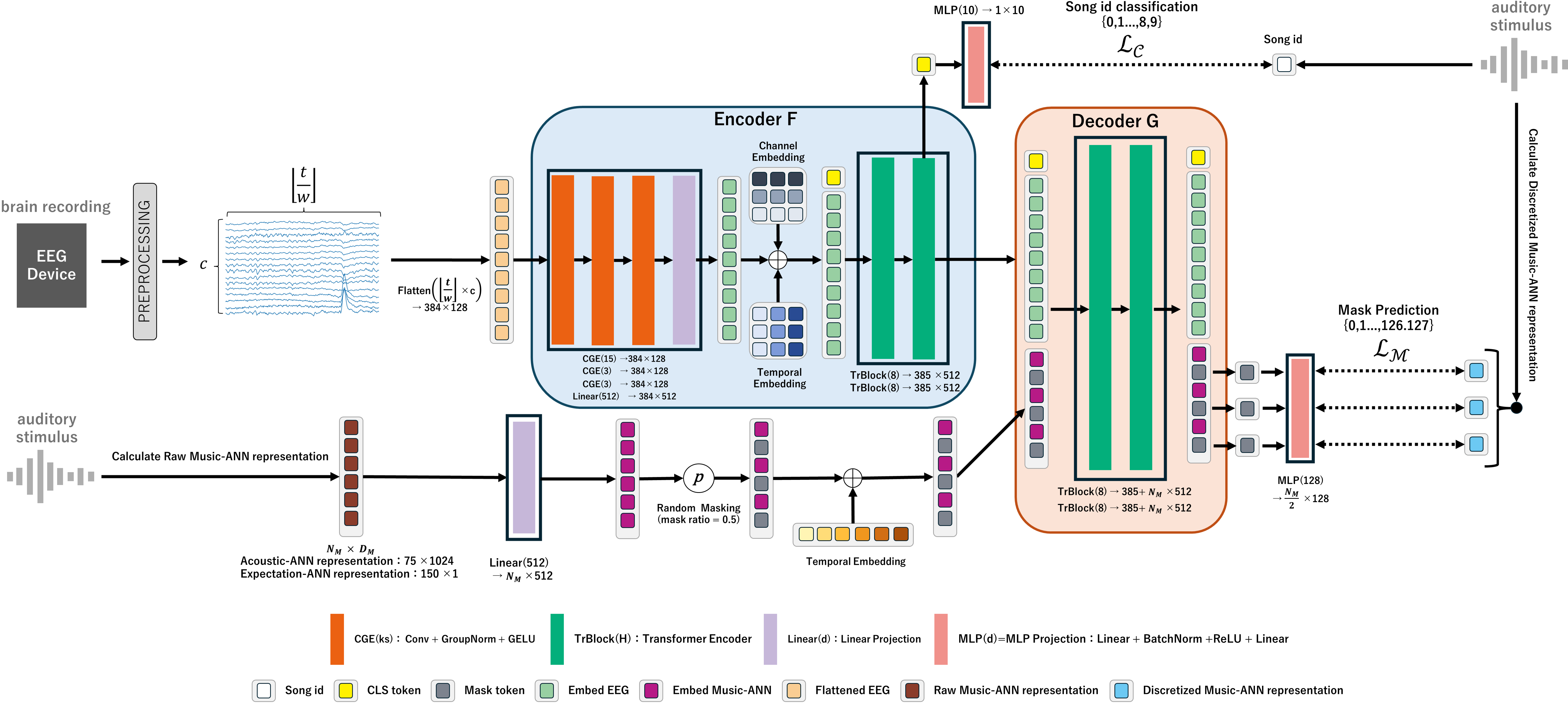
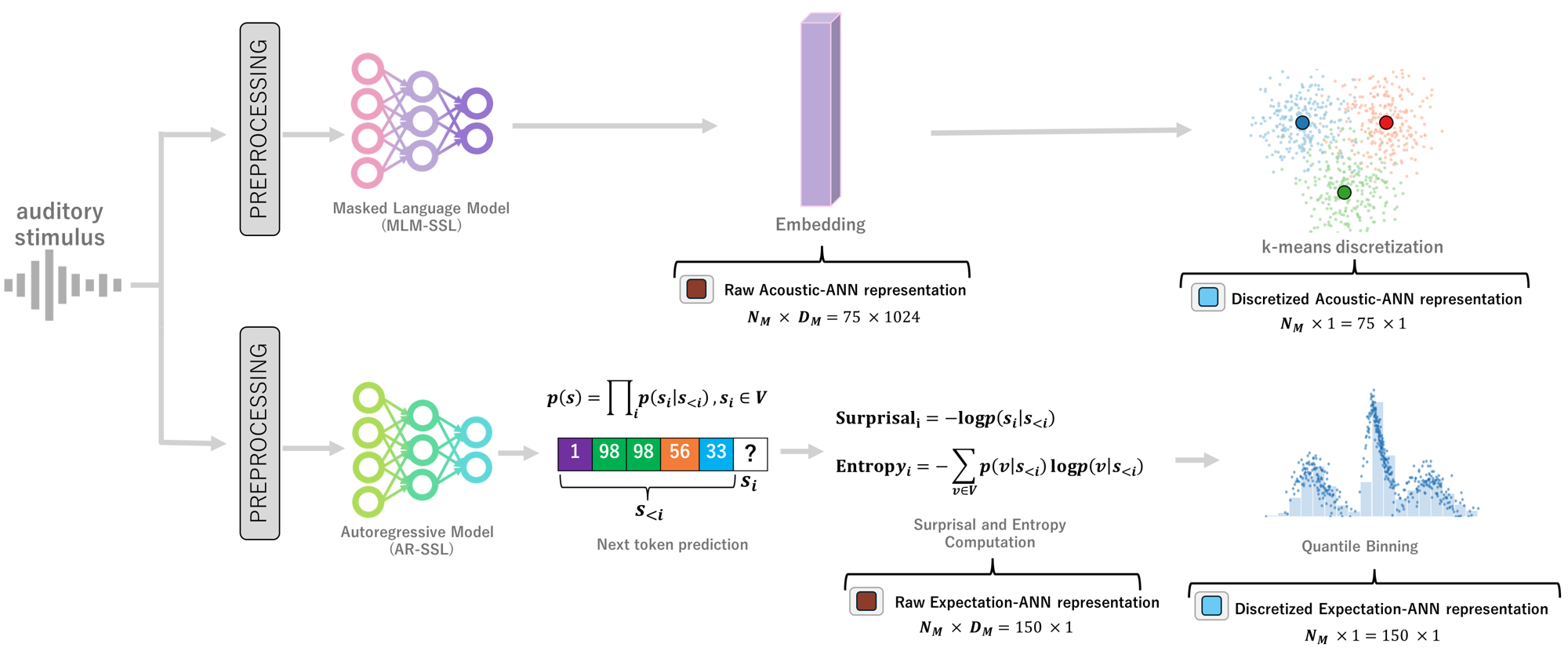
Main quantitative findings at a glance.
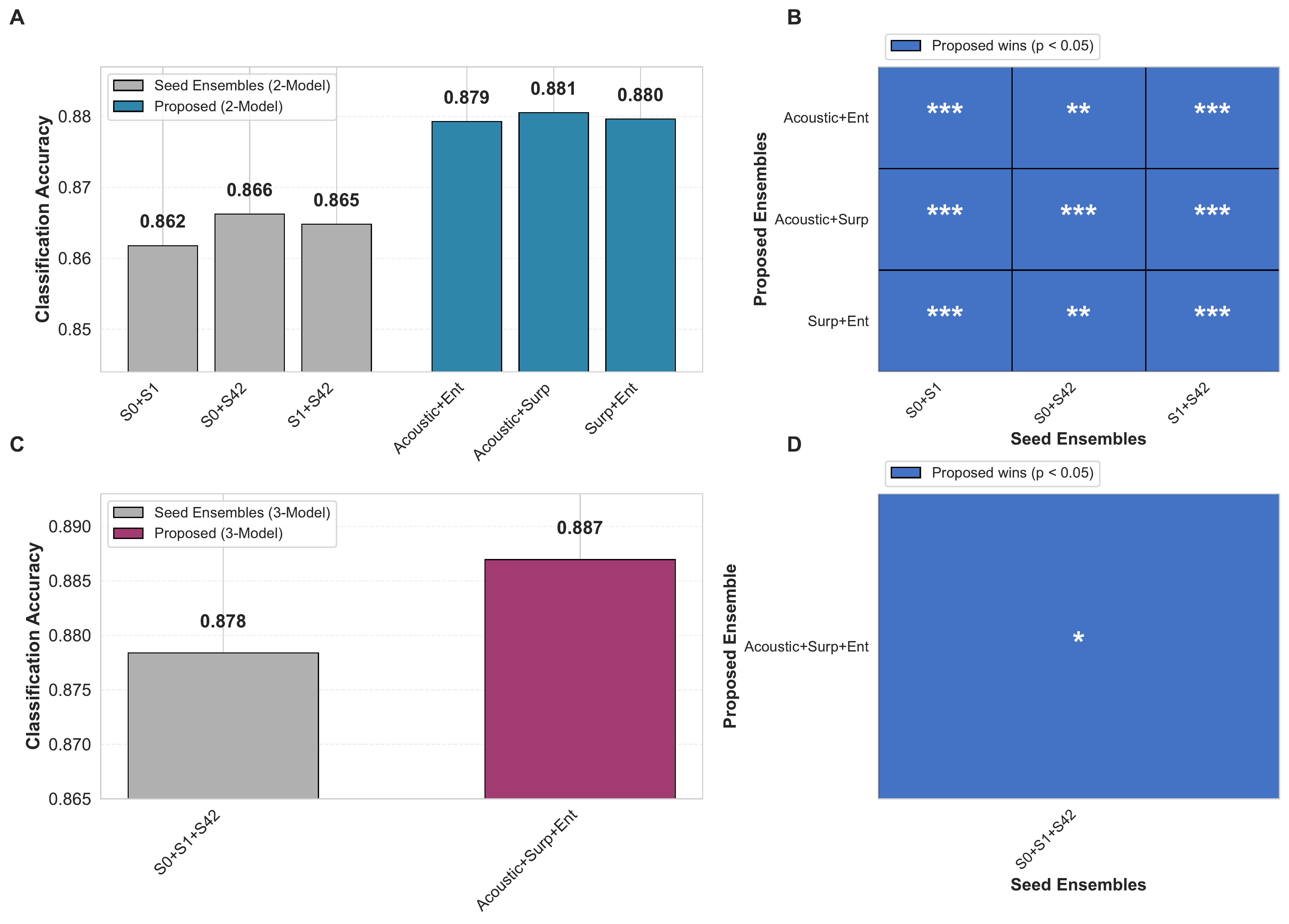
| Category | Model / Ensemble | Accuracy | Notes |
|---|---|---|---|
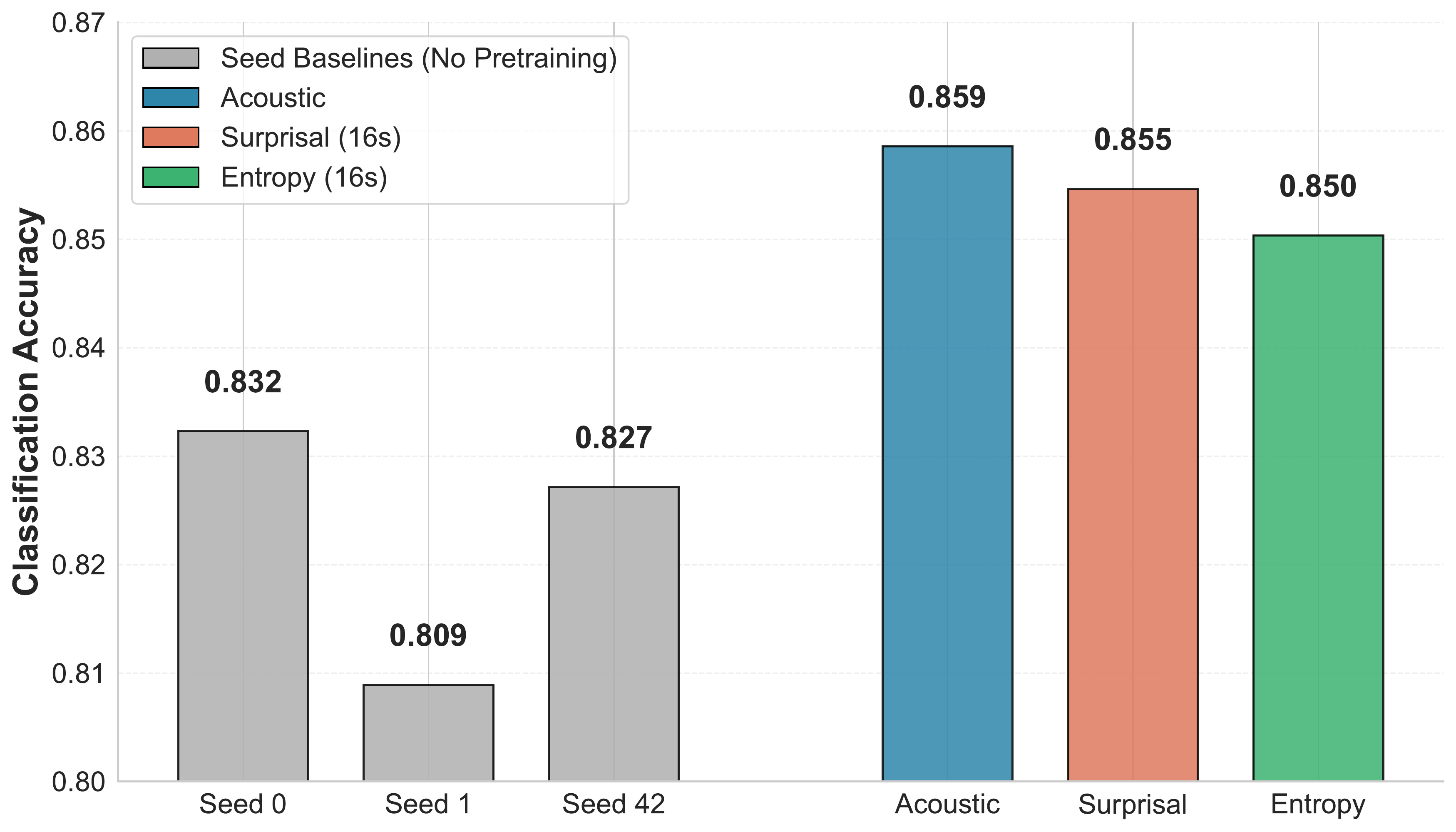
| Baseline (Full-scratch) | Seed 0 / 1 / 42 (mean) | 0.823 (0.832 / 0.809 / 0.827) | Transformer EEG encoder trained from scratch. |
| Single model (pretrained) | Acoustic | 0.859 | Best single model. |
| Single model (pretrained) | Surprisal (16s) | 0.855 | Expectation-related representation. |
| Single model (pretrained) | Entropy (16s) | 0.850 | Expectation-related representation. |
| 2-model ensemble | Acoustic + Surprisal | 0.881 | Probability averaging. |
| 2-model ensemble | Acoustic + Entropy | 0.879 | Probability averaging. |
| 2-model ensemble | Surprisal + Entropy | 0.880 | Probability averaging. |
| 3-model ensemble | Acoustic + Surprisal + Entropy | 0.887 Best | Representation diversity ensemble. |
| Seed ensemble | Seeds 0 + 1 + 42 | 0.878 | Initialization diversity baseline. |
Experiments were conducted on the NMED-T dataset .
Visualization for Surprisal / Entropy Q128 sequences. The page loads three demo tracks and synchronized Surprisal / Entropy data with the 16-second context setting used in the main experiments.
Timeline sync is aligned to segment_start_s, with a hard upper bound of 240 sec
(shorter tracks end at their natural duration).
Discretization method: continuous Surprisal and Entropy sequences were pooled across all songs (NMED-T 10 songs + 3 demo tracks), then feature-wise 128-bin equal-frequency quantile binning was applied. Each frame value was converted to a discrete label in the range 0–127 using the resulting bin boundaries.
The elevated surprisal and entropy values at the beginning of tracks arise from the context-window design.
For each segment, logits are computed using a fixed 16-second lookback window. At song onset, this window
extends beyond the start of the audio, so the missing left context is padded with
special_token_id, a reserved sentinel token used for invalid or masked positions. As a result,
early segments are conditioned partly on synthetic padding rather than real audio history, making the model's
predictions broader and less confident. This increases entropy, which reflects distributional uncertainty,
and also increases surprisal, because the true tokens receive lower probability. The effect lasts for about
13 seconds (window_sec − segment_sec), because segments starting before 13 s still require
left padding. Thus, the early elevation is a systematic artifact of the padding scheme rather than a
property of the music itself.
This section shows a demo video of the demo.py Gradio interface running.
For instructions on how to launch the demo locally and run EEG → Song-ID inference,
see the
Quick Demo (Gradio UI)
section in the GitHub README.
PredANN++ checkpoints are available on Hugging Face 🤗 .
| Model | Pretraining target | Stage | Epochs | Seed | Hugging Face 🤗 |
|---|---|---|---|---|---|
PredANNpp-NMEDT-SongID-EncoderOnly-MuQ-pt10000-ft3500-seed42 |
MuQ acoustic embedding | Song ID classifier | 10k pretrain + 3.5k finetune | 42 | HF |
PredANNpp-NMEDT-SongID-EncoderOnly-Surprisal-ctx16-pt10000-ft3500-seed42 |
MusicGen Surprisal, 16 s context | Song ID classifier | 10k pretrain + 3.5k finetune | 42 | HF |
PredANNpp-NMEDT-SongID-EncoderOnly-Entropy-ctx16-pt10000-ft3500-seed42 |
MusicGen Entropy, 16 s context | Song ID classifier | 10k pretrain + 3.5k finetune | 42 | HF |
PredANNpp-Pretrain-MuQ-ep10000-seed42 |
MuQ acoustic embedding | Multitask pretraining checkpoint | 10k pretrain | 42 | HF |
PredANNpp-Pretrain-Surprisal-ctx16-ep10000-seed42 |
MusicGen Surprisal, 16 s context | Multitask pretraining checkpoint | 10k pretrain | 42 | HF |
PredANNpp-Pretrain-Entropy-ctx16-ep10000-seed42 |
MusicGen Entropy, 16 s context | Multitask pretraining checkpoint | 10k pretrain | 42 | HF |
PredANNpp-NMEDT-SongID-FullScratch-ep3500-seed42 |
- | Full-scratch Song ID classifier | 3.5k training | 42 | HF |
@misc{noguchi2026expectationacousticneuralnetwork,
title={Expectation and Acoustic Neural Network Representations Enhance Music Identification from Brain Activity},
author={Shogo Noguchi and Taketo Akama and Tai Nakamura and Shun Minamikawa and Natalia Polouliakh},
year={2026},
eprint={2603.03190},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2603.03190},
}