Abstract
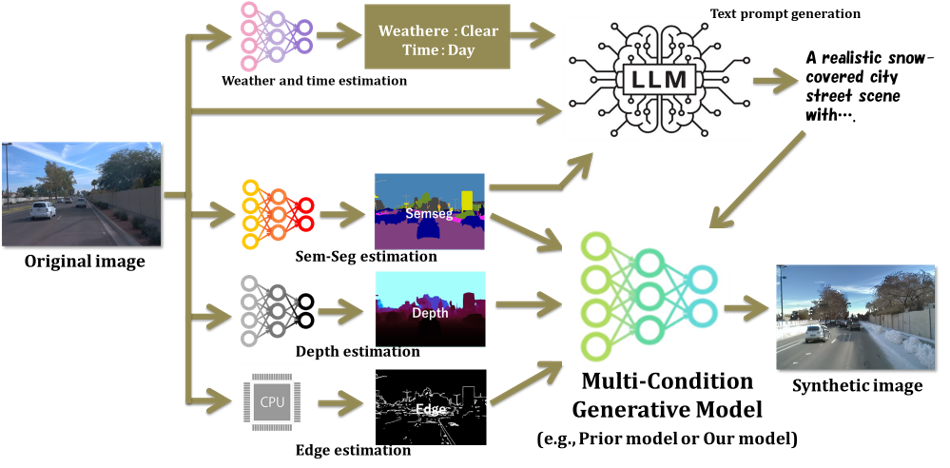
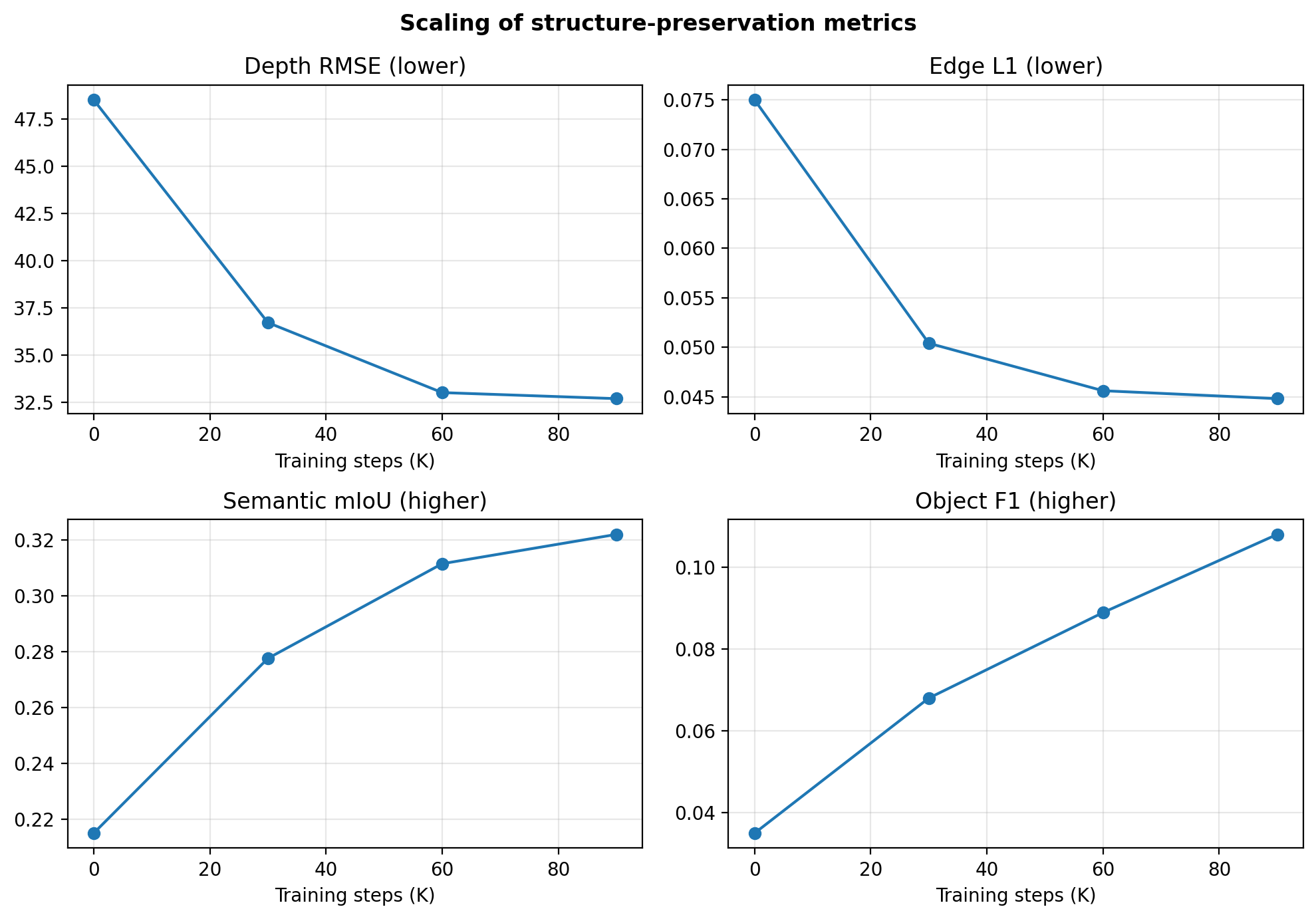
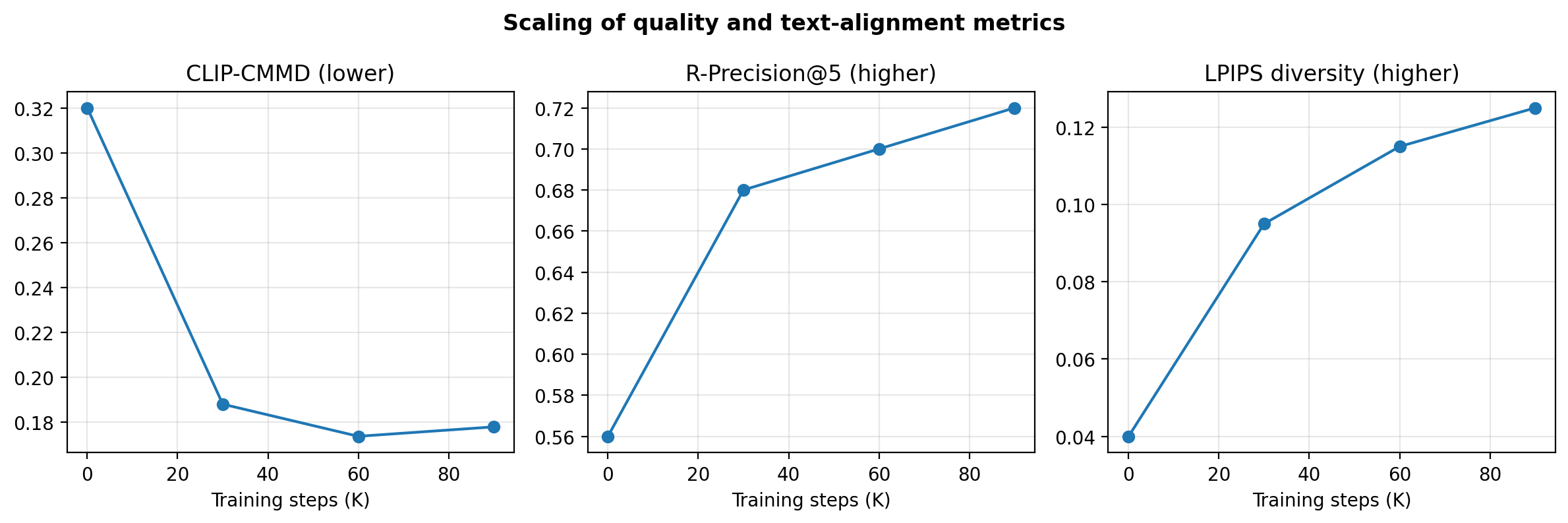
High-level autonomous-driving tasks require more than class masks. They depend on road geometry, distant structure, object presence, lane continuity, and traffic-scene coherence. Existing annotation-conditioned diffusion approaches are promising, but semantic-only control is often insufficient and multi-condition control can introduce destructive conflicts.
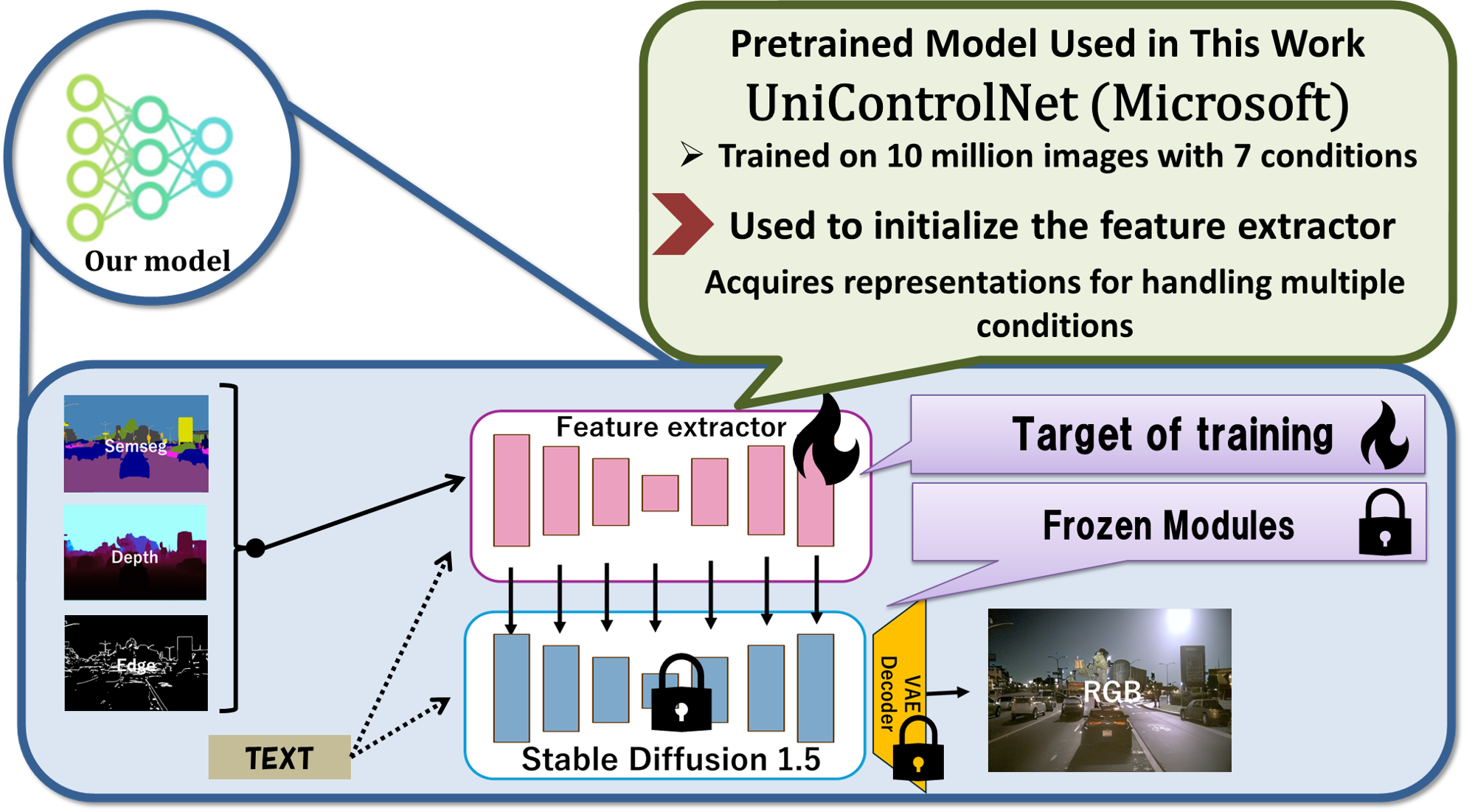
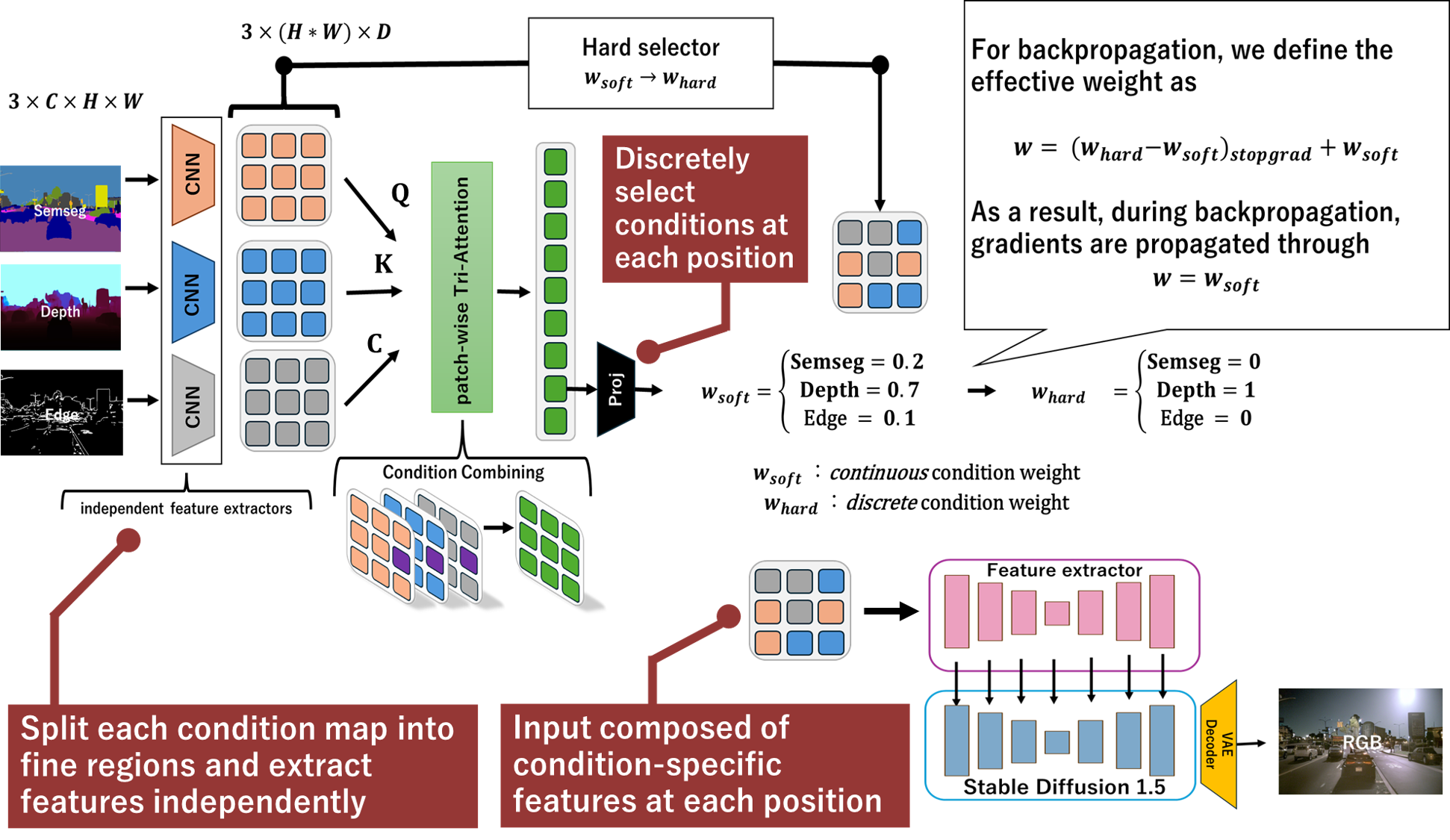
AtteConDA addresses this by combining semantic segmentation, depth, and edge conditions in a Uni-ControlNet-style diffusion framework, while introducing a Patch-wise Adaptation Module (PAM) that performs conflict-aware local condition selection. The repository organizes the practical pipeline -- preparation, prompt generation, training, Waymo inference, and evaluation -- so that new methods can be compared on a shared structure-preservation benchmark.